最近将 Token 翻译成词元之后,又有个词突然变热且暂时没有合适的翻译:Harness Engineering。
不是新模型,不是新框架,甚至不是新工具——就是这么一个词,突然开始出现在各种技术讨论里。
它从哪来的?它在说什么?为什么现在火起来?
我们来拆解三篇相关的重要文章,最后讲讲实践中如何落地。
先说这个词本身
Harness,字面意思是"缰绳"或"挽具"。
放进 AI 工程的语境:Harness 是把 agent 纳入工程系统的那套控制结构——让 agent 的工作变得可约束、可验证、可回放,而不是每次运气好就成功、运气不好就不知道哪里出了问题。
它不是某一个工具,也不是某一个 prompt 技巧。它是一套工程思路:当代码主要由 agent 生成,工程师的工作重心从"写代码"转向"设计让 agent 能够有效工作的环境"。
听起来很虚?下面看具体的。
第一篇:OpenAI,2 月 11 日
这个词真正开始传播,是因为 OpenAI 在 2 月 11 日发了一篇工程博客,标题叫《Harness Engineering: Leveraging Codex in an Agent-First World》。
文章里有一组数字,很多人看完沉默了:
5 个月。3 名工程师。约 100 万行代码。约 1,500 个 PR,平均每人每天 3.5 个。
更关键的是:从第一个 commit 开始,仓库里没有一行代码是人手写的。 连最初的 AGENTS.md——用来告诉 agent 怎么在这个项目里工作的文件——都是 agent 自己写的。
但这不是 vibe coding。
OpenAI 团队在文章里说了一句很关键的话:
早期进展比预期慢——不是因为 Codex 没有能力,而是因为环境没有定义好。
他们发现,agent 卡住的时候,根本原因往往不是模型不够强,而是"环境欠规范"——缺工具、缺约束、缺文档、反馈回路断了。工程师的真正工作,是把这些缺口一个个填上。
文章里有两个具体做法值得记:
AGENTS.md 不是百科全书,是目录。
很多人会把规则文件越写越长,结果 agent 根本分不清哪些规则还有效、哪些已经过时。OpenAI 的解法是:AGENTS.md 只保持约 100 行,作为目录,真正的知识放在结构化的 docs/ 目录里,每条规则单独一个文件,可以独立更新、独立引用。
review 工作也迁移给了 agent。
人类工程师几乎不逐行看代码——PR 的 review 逐步变成 agent-to-agent 模式。人只做一件事:把注意力放在高杠杆的地方——哪里卡了、什么约束需要补、反馈回路在哪断了。
第二篇:Birgitta Böckeler,2 月 17 日
OpenAI 那篇发出来 6 天后,Thoughtworks 的杰出工程师 Birgitta Böckeler 在 Martin Fowler 的博客上发了一篇读后感,对 harness 这个概念做了补充和拆解。
她把 harness 的组成归纳成三块:
- 上下文工程:把知识和约束变成持久的工件——动态知识库、实时数据接入(可观测性、浏览器导航)。
- 架构约束:确定性检查工具、结构测试,强制模型在有限的解空间里工作,而不是每次随机发挥。
- 垃圾收集:定期让 agent 去维护文档和架构的一致性,主动对抗熵增。
她还提出了一个有趣的类比:harness 可能是下一代的"服务模板"。 现在团队新建项目会从一套黄金路径脚手架开始,未来可能从一套 harness 模板开始——里面预置了 agent 的工作规范、架构约束、验证门禁。
但她也指出了一个在 OpenAI 原文里讲得不够清楚的缺口:
很多 harness 的讨论把重点放在"内部质量与可维护性"上,但**功能与行为的验证(verification of functionality/behaviour)**反而讲得不够清楚。
这句话说的其实是:如果 harness 只做"治理",你会得到一个结构整齐但不一定好用的系统。验证,才是闭环里最后那道门。
第三篇:Anthropic,3 月 24 日
Anthropic 工程博客最近发了一篇文章,专门讲他们怎么用 harness 解决"长程 agent 任务"的质量问题。这篇最有工程含量,也最具体。
他们发现 agent 在长任务里有两个顽固的失败模式:
一是上下文衰减。 任务越长,模型越容易"迷失"。上下文窗口快满时,有些模型甚至会产生某种"焦虑",提前草草收工。
二是自我评估偏宽松。 让 generator 评价自己写的代码或设计,它几乎总会给自己打高分——哪怕人类一眼就能看出质量很差。“调教一个独立的、持怀疑态度的 evaluator,远比让 generator 对自己的工作保持批判性眼光更容易实现。”
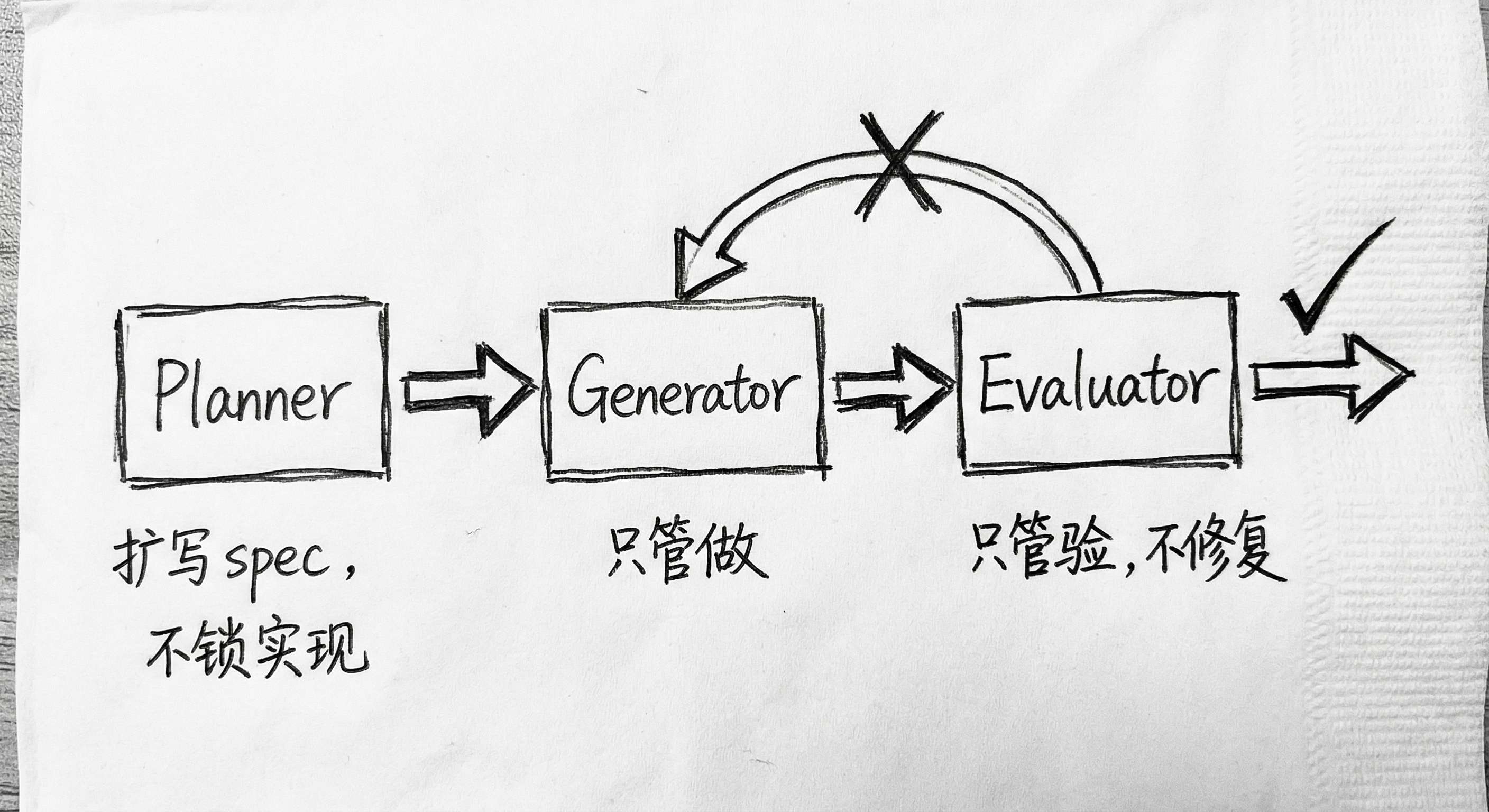
解法是借鉴了 GAN 的思路:把生成和评估拆开,交给不同的 agent。
具体是三个角色:
- Planner:把简短的需求扩写成带约束的 spec。但刻意不过早锁定实现细节——防止早期的错误假设在下游放大。
- Generator:按计划逐步实现,只管"做"。
- Evaluator:用 Playwright 真实跑页面、点按钮、发请求,找 bug。设定验收阈值,不达标就打回,并给出可复现、可行动的具体反馈——不是"有问题",而是"第 3 步点击后 API 返回 500,复现命令是 X"。
他们有一个亲测的对比数据:
| 单 agent | 三代理 harness | |
|---|---|---|
| 时长 | 20 分钟 | 6 小时 |
| 花费 | $9 | $200 |
| 质量 | 功能看起来跑通,但核心 bug 没被发现 | 完整可用,真实问题被修复 |
成本高了 20 倍,但质量不在同一个维度。
他们还总结了一条值得反复看的原则:
harness 里的每一个组件,都编码了一个关于"当前模型做不好什么"的假设。
所以 harness 应该随着模型能力提升而动态瘦身。他们从 Opus 4.5 升级到 4.6 之后,发现原本用来防跑偏的 sprint 分解机制可以去掉了——新模型已经能自己管住任务节奏。
落地:用 SpecKit 做上半场,加一个 Evaluator Agent 收尾
读完三篇文章,我觉得最可行的落地路径是这样的:
用 SDD 把"意图"变成工件,再用 Evaluator Agent 做强制验收。
为什么 SDD 能解决上半场的问题?
agent 跑偏,根本原因大多数时候不是模型不够聪明,而是它根本不知道你想要什么。你在 prompt 里说的那几句话,含糊、易丢失、无法约束后续每一步。
SDD(Spec-Driven Development)的思路很直接:先把意图变成结构化的文件,再让 agent 去执行。 文件是持久的、可引用的、可修改的——比 prompt 可靠得多。
GitHub 开源的 SpecKit 把这套流程拆成了五步:
- Constitution:定下项目的"不变原则"——代码风格、测试要求、性能红线、架构约束。这个文件相当于你对 agent 说的第一件事,也是最重要的一件事。
- Specify:描述你要做什么、为什么做。只说"what"和"why",不说"how"——避免过早锁死实现细节。
- Plan:让 agent 根据 spec 设计技术方案。
- Tasks:把 plan 拆成一条条可执行、可追溯的任务清单。
- Implement:agent 按任务逐条落地。
这五步里最关键的是前两步。Constitution + Spec 就是你给 agent 的"缰绳"——它不需要每次靠 prompt 猜你的意图,因为意图已经以文件的形式住在仓库里了。
安装也很简单:
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git
specify init MY_PROJECT --ai claude
然后在 Claude Code 里跑 /speckit.constitution,开始填写项目原则,之后按流程走就行。
加上 Evaluator Agent,harness 才算闭环
这里有一个容易被忽略的细节:SpecKit 本身其实已经内置了验证能力,只是它们默认需要你手动调用。
具体来说,SpecKit 的每个 task 里本身就包含了测试内容,并且有配套的扩展来做对齐检查:
- Verify Tasks 扩展:专门用来检测"phantom completion"——也就是任务在
tasks.md里被标记成[X]了,但实际根本没有对应实现。这是 agent 最常见的自我欺骗方式。 - V-Model 扩展:强制要求每个开发 spec 都配对一个测试 spec,保证验证条件在任务开始前就写清楚,而不是事后补。
/speckit.analyze:分析需求和当前实现之间的对齐情况,找出偏差——不是跑测试,而是从 spec 层面检查"做的跟说好的是不是一回事"。
这些能力都在。问题是:它们在等你去调用,而不是自动触发。
这正是落地的关键所在。SpecKit 社区已经有了一个 Ralph Loop 扩展,专门用来把这条手动调用链自动化。
它的每个迭代周期非常固定:
- 读取
tasks.md,找出第一个未完成的任务 - 实现它,把 checkbox 标为
[X] - 把本次迭代的变更、教训写入
progress.md - 自动 commit
- 编排程序检查终止条件,再循环
用法也直接:
/speckit.ralph.run --max-iterations 5 --model claude-sonnet-4-6
还有两个不容易注意到但很重要的设计:一是中断恢复,它会根据 checkbox 状态跳过已完成的任务,中途停掉再继续不会重复做;二是失败熔断,连续 3 次失败自动停止,不会让 agent 在死胡同里无限转圈。
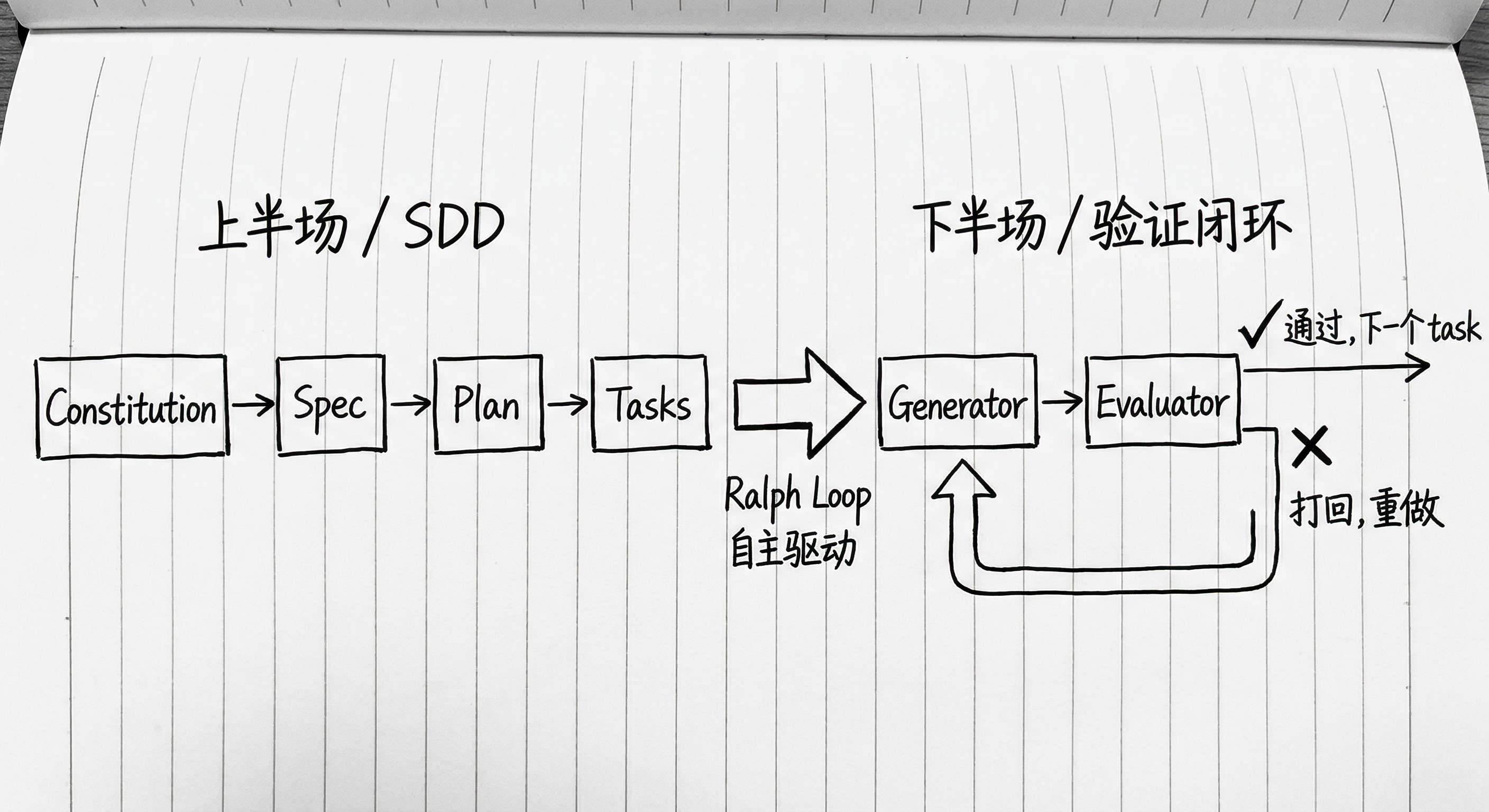
把这几块拼在一起,整条流程是:
Constitution + Spec(意图落盘,约束写死)
→ Plan + Tasks(含配对测试 spec,验收条件前置)
→ Ralph Loop 驱动 Generator 逐 task 实现
→ 每 task 结束自动触发:
/speckit.analyze ← 需求与实现对齐检查
Verify Tasks ← 检测 phantom completion
pytest / playwright ← 真实跑验证
→ 有任何一项不通过,打回 Generator 重做
→ 循环,直到所有验收通过
这个结构的核心是:验证不是最后才做的事,它从 spec 阶段就已经被前置了;agent 不是做完等你检查,而是自己跑完验证再汇报。
这样,SDD 解决的是"agent 知道要做什么",Ralph Loop + Verify Tasks + analyze 解决的是"agent 能自主确认有没有真的做到"——两者加在一起,才是一个完整的 harness 闭环。
最后
Harness Engineering 这个词火起来,不是因为它发明了什么新东西,而是因为它给一个大家已经隐约感觉到的问题提供了一个名字:
当 agent 能写代码之后,工程师的主要工作是什么?
OpenAI 的回答是:设计环境和反馈回路。 Anthropic 的回答是:把验证做成独立的、强制的角色。 Böckeler 的提醒是:别光治理,要验收。
三个回答指向同一件事:写提示词只是开始,能把 agent 管住、验收、形成闭环,才是真正的工程能力。
接下来会用实际项目,展示这套基于 SDD 的 Harness Engineering 实践,如果对你有帮助,欢迎关注「Agent工程手记」。
参考文章:
- Harness engineering: leveraging Codex in an agent-first world — OpenAI,2026.02.11
- Harness Engineering — Birgitta Böckeler @ martinfowler.com,2026.02.17
- Harness design for long-running application development — Anthropic Engineering